

Imagine a world where diagnosing diseases from medical images takes minutes instead of hours, cutting a hour-long review down to minutes. AI driven image segmentation (software that automatically identifies and isolates parts of a scan, such as organs or tumors) aims to make this vision a reality.
Yet most segmentation models still depend on large, expert annotated datasets, with each manual outline consuming clinicians’ precious time. The challenge intensifies across different scan types (for example, X rays, where overlapping bones hide soft tissues; CT scans, which require perfect alignment of hundreds of cross-sectional slices; and ultrasounds, whose appearance shifts dramatically with the technician’s technique). Even advanced tools like the Segment Anything Model (SAM) and its medical variants (SonoSAMTrack, SAM Med2D, SAM Med3D) rely on manual or semi-automated prompting and struggle when expert labels are scarce or inconsistent.
The solutions enabled by SAM with foundation models
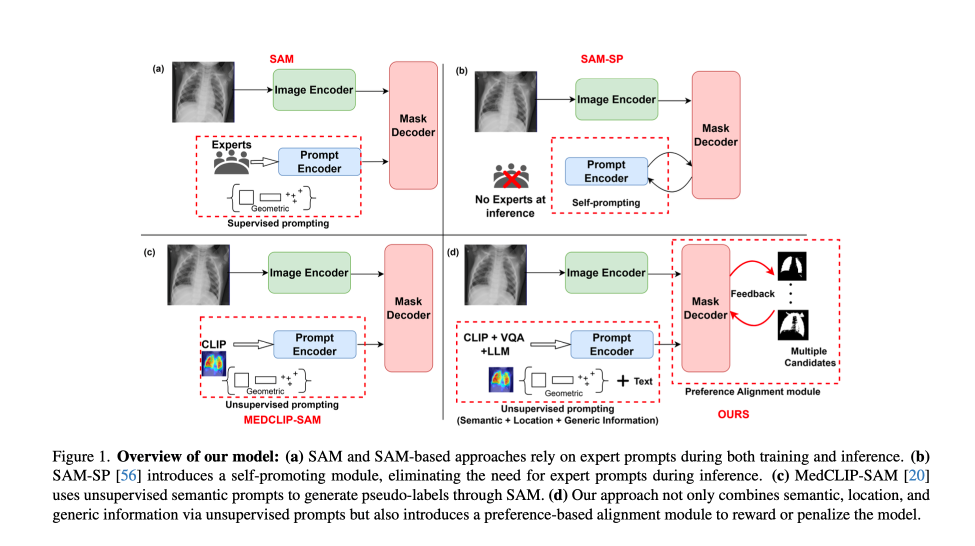
This paper introduces a method that reduces annotation overhead while improving segmentation accuracy through two key innovations. The first innovation is a prompting module that extracts semantic information (what the structure is), spatial information (where it sits), and morphological information (its shape and size) without any human provided labels. The second is a preference-based optimization strategy inspired by techniques used to align language models. While unsupervised learning and preferential ranking have reshaped the training paradigms of large language models, their application in medical imaging has remained limited due to the high complexity and domain specific nature of annotations.
This work addresses those challenges by unlocking the potential of such techniques for medical imaging, where annotation is both costly and scarce. Together, the proposed components enable semi supervised training (learning from a small set of labeled scans alongside a larger pool of unlabeled ones) of SAM-based architectures without the need for explicit reward models or fully annotated datasets. These advancements solve key limitations of current models by automating the extraction of information and making model predictions better match human judgment. This creates a more scalable, annotation-efficient, and adaptable training process that can accelerate the development of foundation models in medical imaging.
A new modality-agnostic design
The proposed method is especially well suited to healthcare environments where expert annotation is a limited resource. It opens the door to deploying segmentation models in low resource clinics (such as small community hospitals or rural health centers with limited access to imaging specialists) enabling AI support for radiology in underserved areas.
The method’s modality agnostic design (tested on X rays, ultrasounds, and 3D CTs) makes it broadly applicable across clinical imaging pipelines. Additionally, the framework’s ability to integrate simulated feedback means it could be extended to other domains that require human judgment but lack annotated datasets, such as pathology or real time interventional imaging.
Methodology
The approach consists of two stages: (1) unsupervised prompt generation and fine tuning, and (2) alignment through direct preference optimization. Each stage is designed to reduce dependence on labor intensive human prompting and labeling while extracting rich supervisory signals from pretrained multimodal and segmentation models. This design also enables a paradigm for continuous learning, allowing models to adapt over time to new data and institutional preferences (paving the way for more personalized care, where models can be tailored to the unique characteristics and requirements of individual hospital sites.)
In the first stage, the system generates structured prompts using three models: BiomedCLIP (a model that creates visual summaries like heatmaps and bounding boxes to highlight important parts of an image), MedVInT (a visual question answering model that answers questions about medical images), and GPT 4 (for general semantic information.)
- Visual prompts are derived by passing the image and a disease or organ label (for example, “chest X ray” or “left kidney”) into BiomedCLIP, which produces gScoreCAM saliency maps. A saliency map is a type of heatmap that highlights the regions in an image that most influence the model’s decision. These maps are post processed using dense CRFs that smooths rough heatmaps into more coherent and cleaner regions. From these refined maps, the system extracts bounding boxes, or rectangular boxes drawn around objects of interest, and sampled point prompts that are selected points inside those objects.
- Textual prompts are constructed by prompting MedVInT with structured questions (for example, “What is the shape of the tumor and where is it located?”). These answers, combined with GPT 4 descriptions of disease or organ features, are encoded and provided as input to the SAM prompt encoder. The prompt encoder is a part of the model that processes and understands the combined visual and textual information.
These visual and textual embeddings are fused into a common prompt space and used to fine tune the SAM Med2D encoder and mask decoder on a small, annotated subset, typically just 10 percent of the dataset. We selected 10% of the data to simulate a scenario with minimal reliance on fully annotated data, where the majority of the dataset requires only preference annotations. This fusion allows the model to internalize both spatial and conceptual representations of anatomical features, helping it work more accurately across different scanning scenarios, such as images from various machine models, lighting conditions, or patient positions.
In the second stage, the model transitions to semi supervised training, a method where the model learns from a small amount of labeled data along with a larger amount of unlabeled data, by simulating human feedback on unlabeled data. For each input, it generates multiple segmentation candidates by applying thresholding, a process that sets a cutoff value so only the most confident areas are selected, across different levels such as between 0.3 and 0.6.This turns the model’s confidence scores into binary masks by including pixels that are above the chosen cutoff.
These candidates are then rated using simulated overlap scores with the ground truth. Ground truth refers to the correct or true label that a model should ideally predict. The ratings are mapped into a 4-point preference scale.
Rather than training a separate reward model, as in reinforcement learning with human feedback where a special model learns to give scores, the authors employ a Direct Preference Optimization (DPO) loss. DPO is a method where the model learns from direct pairwise comparisons, like choosing the better of two sketches, to directly prefer higher quality outputs. This loss function compares the likelihoods of preferred versus less preferred outputs, using a modified Bradley Terry model, a statistical method that turns multiple win-lose comparisons into a global ranking and adjusts model parameters to favor higher rated segmentations.
The model is updated to improve consistency with these simulated preferences while staying close to the initially fine-tuned policy. By eliminating the need for explicit reward models or domain specific reward engineering, DPO significantly simplifies the optimization pipeline while preserving performance gains. The optimization pipeline is the overall process by which the model becomes better during training.
This setup enables efficient end to end training with minimal annotation, while still capturing nuanced human like feedback on segmentation quality.
Implications and real-world impact
The method was rigorously evaluated across three benchmark datasets, each representing a distinct imaging modality and a clinically significant segmentation task:
• Chest X-ray (COVID-QU-Ex): A large dataset comprising 27,132 training images and 6,788 test images used for lung segmentation tasks.
• Breast Ultrasound (BUSI + UDIAT): 810 ultrasound images, with 600 used for training and 210 for testing, combining benign and malignant breast tumor cases.
• Abdominal CT (AMOS-CT): 200 annotated CT scans for training and 100 for validation, covering segmentation of 15 different abdominal organs.
These datasets enabled evaluation under both 2D and 3D imaging contexts, ensuring generalizability of the proposed method.
Quantitative performance in low-data settings reveals the strength of this approach:
- With just 10% labeled and 10% unlabeled data, the model achieved a Dice score of 78.87 on chest X-rays—substantially outperforming established baselines such as nnU-Net (60.97), SAM-Med2D (67.81), and self-prompted SAM (68.41).
- On breast ultrasound images, the Dice score rose from 75.88 (with 10% labeled + 10% unlabeled data) to 88.15 (at 10% labeled + 40% unlabeled), demonstrating consistent gains with more unlabeled training data.
- For abdominal CT scans, the model achieved 84.30 Dice with only 10% labeled and 40% unlabeled data, outperforming SAM-Med3D and approaching the accuracy of its own fully supervised counterpart.
- These results reflect a clear trend: simulated preference alignment can effectively replace manual annotation in scaling model performance, particularly in data-scarce environments. Notably, performance improves steadily with more unlabeled data incorporated into the alignment stage:
- With only 10% labeled + 10% unlabeled, the framework nearly matched fully supervised performance (78.87 vs. 79.13 Dice on chest X-rays).
- With 40% unlabeled data, scores reached 89.68 on chest X-rays, 88.15 on breast ultrasound, and 84.30 on abdominal CT, up from 78.87, 75.88, and 77.69 respectively when using 10% unlabeled data.
Qualitative comparisons further validate the approach: segmentation boundaries produced by the model are cleaner and more anatomically accurate, particularly in complex regions like tumors or spleen liver interfaces. Ablation studies (comparable to removing ingredients from a recipe one at a time to see which one makes the biggest difference) were conducted to isolate the roles of key design elements:
• Excluding MedVInT VQA inputs resulted in a 2.25 point drop in Dice score on chest X rays.
• Removing GPT 4 descriptions led to further decline.
• Replacing preference ranking with selection of only the best candidate degraded performance.
Together, these results confirm the complementary nature of multimodal prompting and preference-based learning while also demonstrating the framework’s robustness, scalability, and clinical relevance.
The model also showed robustness to noise in rating mechanisms, suggesting that even imperfect feedback signals are sufficient for effective alignment. This tolerance to noise enhances its practical deployment in real world scenarios where perfect annotations are rare.
Conclusion: Reimagining techniques to solve the most complex problems in healthcare
This work advances the state of semi supervised segmentation in medical imaging by combining foundation model prompting with preference-based learning. Its modular design, with prompt generation via BiomedCLIP, MedVInT, and GPT 4, followed by alignment via DPO, offers a scalable recipe for training strong segmentation models with minimal labeled data.
The ability to simulate annotator feedback and train without an explicit reward model makes this method both practical and adaptable, particularly for domains like healthcare where expert supervision is costly and constrained.
Additionally, quicker and more accurate segmentation can accelerate the entire diagnostic process,. For example, in emergency care settings where time critical diagnoses are essential, faster segmentation of chest X rays or CT scans can significantly impact patient outcomes.
Beyond traditional imaging, the flexibility of this approach also opens possibilities for other fields that depend on image-based judgment but lack large labeled datasets, such as pathology or real time interventional imaging. By enabling continuous learning and adaptability, these methods lay the groundwork for deploying robust AI solutions across a wide range of clinical environments.
It signals a broader trend: that techniques from NLP, like preference modeling and prompt engineering, can be reimagined to solve core problems in vision, with real world impact across clinical AI workflows.



