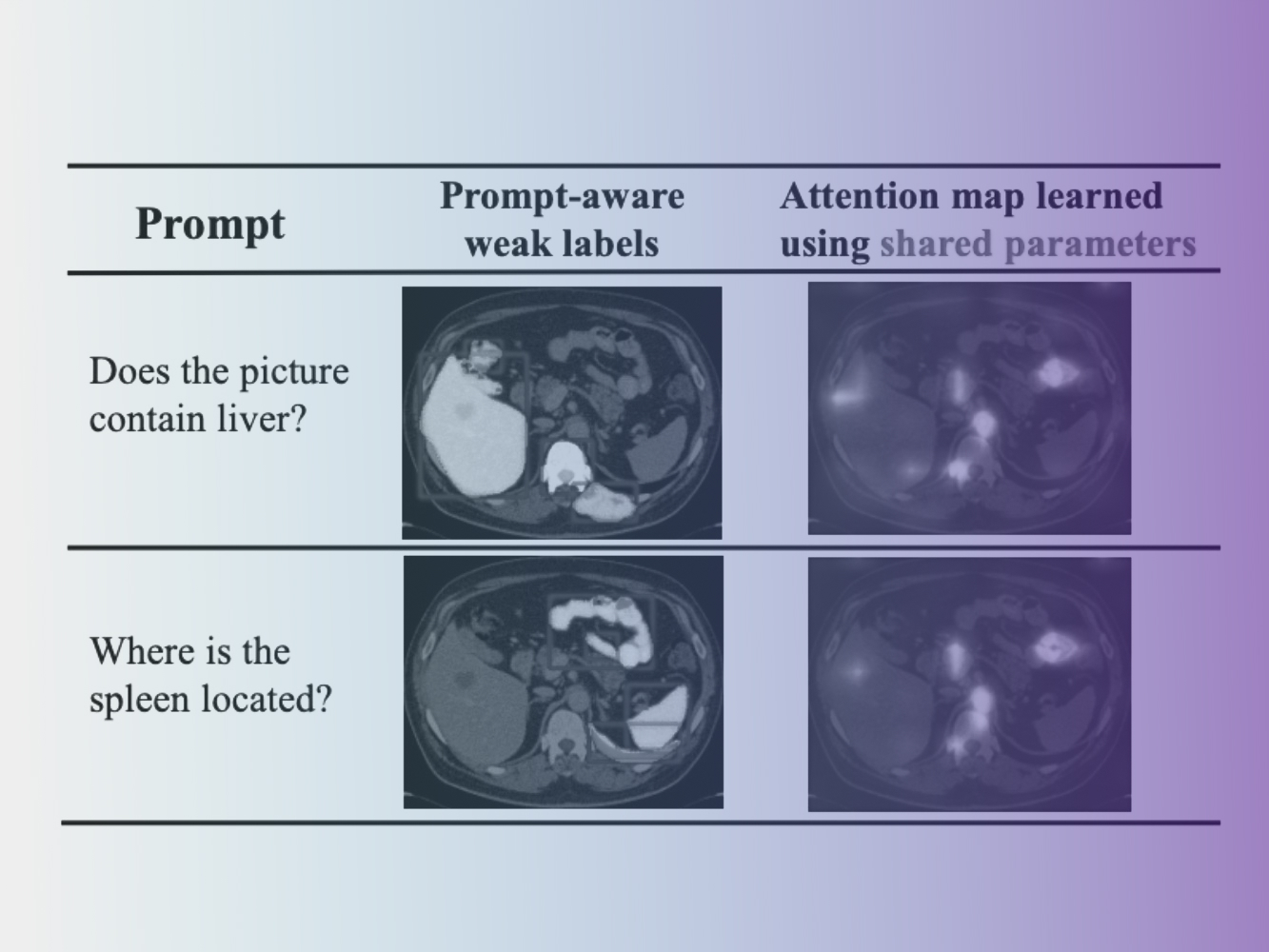
Medical Large Vision-Language Models (Med-LVLMs) often exhibit suboptimal attention distribution on visual inputs, leading to hallucinated or inaccurate outputs. Existing mitigation methods primarily rely on inference-time interventions, which are limited in attention adaptation or require additional supervision. To address this, we propose A3TUNE, a novel fine-tuning framework for Automatic Attention Alignment Tuning. A3TUNE leverages zero-shot weak labels from SAM, refines them into prompt-aware labels using BioMedCLIP, and then selectively modifies visually-critical attention heads to improve alignment while minimizing interference. Additionally, we introduce a A3MOE module, enabling adaptive parameter selection for attention tuning across diverse prompts and images. Extensive experiments on medical VQA and report generation benchmarks show that A3TUNE outperforms state-of-the-art baselines, achieving enhanced attention distributions and performance in Med-LVLMs.
Concept only. This work is in concept phase and may never become a product. Not for Sale. Any reported results are preliminary and subject to change. Not cleared or approved by the U.S. FDA or any other global regulator for commercial availability.